Reflection – Week 6
This week, we explored Algorithmic Identity through Data Input, Output and Categorisation
This week’s workshop has profoundly changed how I understand the construction of digital identity. By working through the stages of input, output and process, I was able to see how my presence on digital platforms is shaped by platforms interpreting and repurposing my data.
In the input stage, I reviewed platforms I frequently use: Instagram, Twitter, and two Chinese apps Weibo and Rednotes. I was struck by how UK platforms make their data collection policies transparent and accessible, while the Chinese platforms’ privacy agreements were hard to locate and less specific. Before this session, I was unaware of how much behavioural data on the platforms, such as likes, saved posts, comments, even “private collections” could be logged and analysed. This raised questions for me about how much control we really have over our digital selves. Social media is often understood as a space for self-expression, but what we have expressed becomes measurable traces that feed algorithmic systems.
During the output task, I examined my advertising profile on Instagram. Although I never post content related to fashion or follow fashion influencers on that platform, I constantly receive clothing ads from Amazon and ASOS. This suggests that even though I explicitly refused cross-platform data tracking, Instagram may still access or infer behaviours from my activity on other platforms. This made me question the transparency and boundaries of data tracking practices. Can we truly exert complete control over how platforms track and store our data?
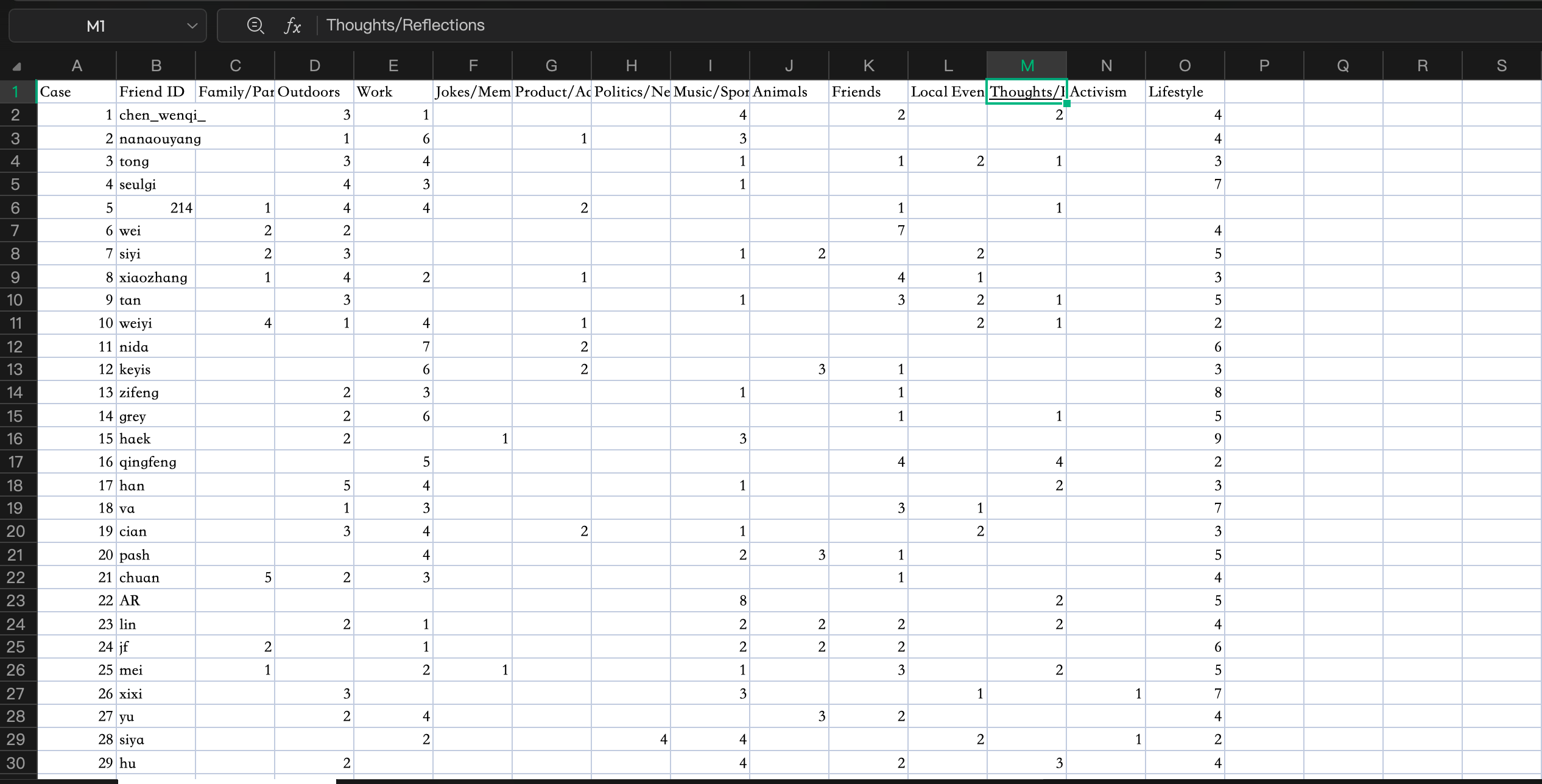
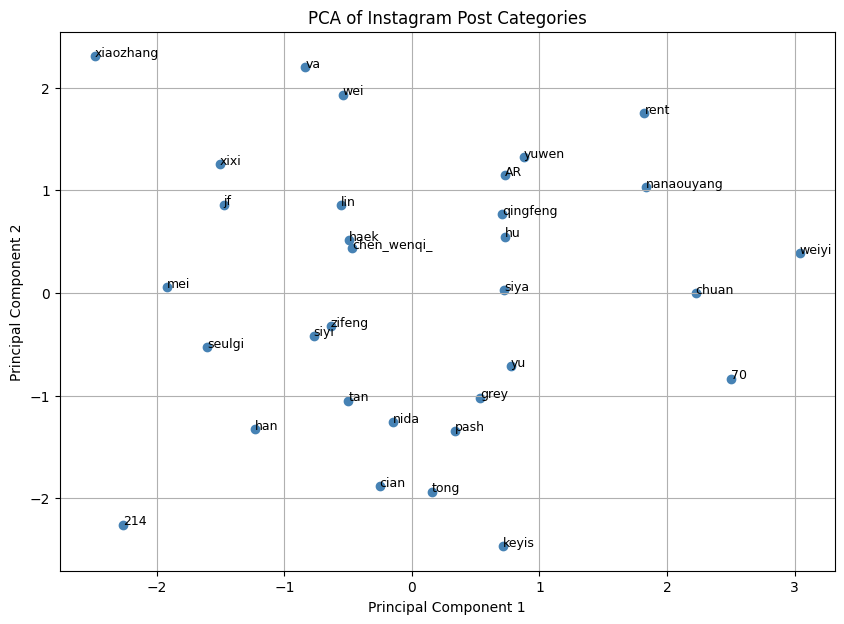
In the categorisation task, we needed to categorize posts from 32 friends using Sampter's (2018) classification system, which proved particularly challenging. I chose Instagram for my records, but I find some problems soon. As a photo-sharing social media platform, many posts have multiple dimensions: a single post might contain multiple photos on different themes, and even a single photo might imply multiple emotions. For example, a friend shared a photo of herself reading on a lawn in a park, presenting three labels: lifestyle, outdoor scene, and book recommendation, but I had to choose only one. Our tutor advised us to consider the poster’s primary intention, which helped, but I still felt uneasy. When defining the content of others' posts, I always felt I was oversimplifying, sometimes even inappropriately. This tension made me reflect on how algorithmic categorisation may simplify subtle expressions in ways that are not only inaccurate but also unfair.
For my dataset, I labeled each friend's 15 posts as a dominant category, such as "Lifestyle," "Work," or "Thoughts/Reflections," ultimately resulting in a frequency-based classification matrix. While the structure is clear, I know that this method inevitably introduces the bias of a researcher's perspective. In forcibly assigning a single label to ambiguous content, I am also repeating the simplification logic of platform algorithms, sacrificing the richness of expression, emotion, and context to arrive at a rational, objective, and visual dataset.